
CODENAVY
Training, Validation, Testing Dataset 본문
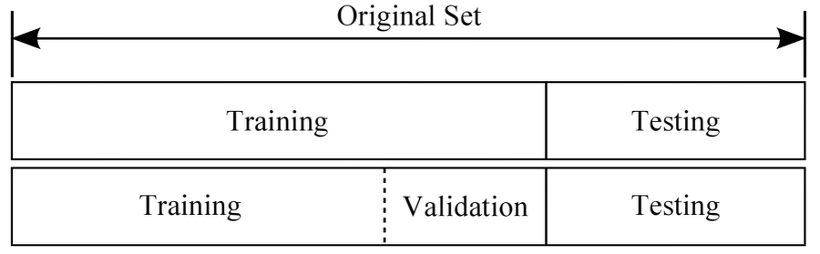
우리가 가지고 있는 데이터 전체를 total data라고 할 때, total data로 모델을 학습시키지 않고, total data의 일부만 가지고 학습시킨 뒤, 나머지 일부 data를 가지고 모델의 성능을 평가하게 된다. 모델을 학습시킬 때 사용되는 데이터(또는 데이터셋)를 training dataset, 그리고 평가에 사용되는 데이터를 testing dataset이라고 한다.
1. 학습데이터(Training Dataset)
- 피쳐(X_train)와 정답(y_train)이 모두 존재하며, 학습을 위해 사용되는 데이터
2. 평가데이터(Testing Dataset)
- 피쳐(X_test)와 정답(y_test)이 있지만, 모델은 학습된 모형을 바탕으로 피쳐(X_test)로부터 예측값을 도출한다.
- 즉, 정답(y_test)은 예측값을 도출하는 과정에서는 사용되지 않고, 성능 측정에만 사용된다.
모델이 training data를 통해 학습하고, testing data를 통해 성능을 평가하는 과정은 수학 문제집을 푸는 과정에 빗대어 설명할 수 있다.
1) 먼저 수학에 대한 지식이 0인 상태에서 문제-정답지를 보며 수학의 원리를 배운다.
(= 모델이 training set에 있는 feature-answer를 학습한다.)
2) 어머니에게 정답지를 뺏겨, 정답지가 없는 상황에서 수학 문제를 푼다.
(= 모델이 testing set에 있는 feature에 대해 예측치를 도출한다.)
3) 문제를 모두 풀고난 후, 본인의 답과 정답지의 답을 비교하며 점수를 매긴다.
(= 모델이 testing set의 feature로부터 도출한 예측값과 testing set의 실제 정답을 비교하여 성능을 측정한다.)
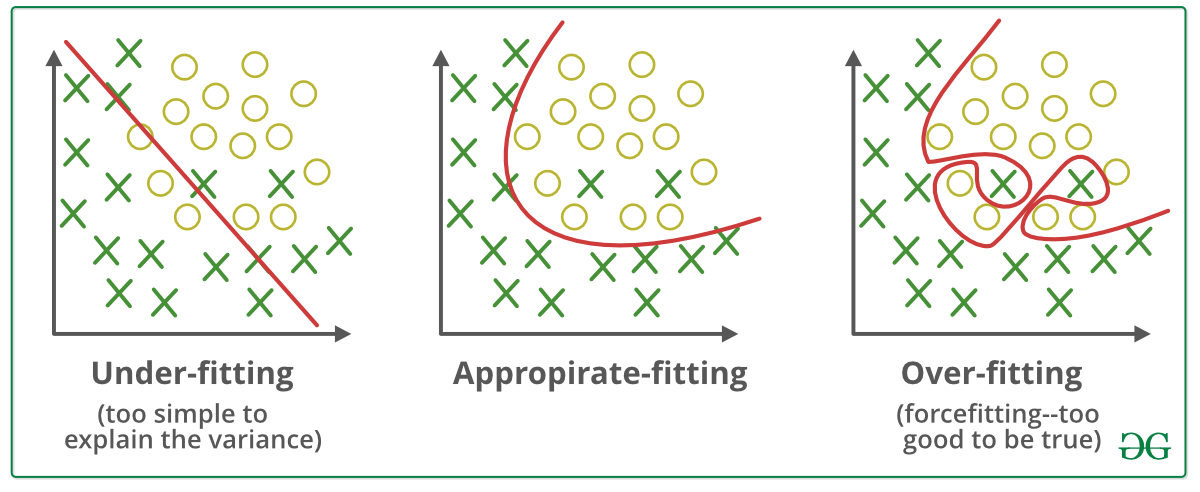
하지만 training set을 모두 학습하고 난 후, 모델의 성능이 항상 좋기만 할까? 그렇지는 않을 것이다. 많이 발생하는 문제점 중 하나로 overfitting(과적합)이 있는데, 이는 가장 오른쪽 그림에서 볼 수 있듯이 training dataset의 패턴만 지나치게 익혀, 새로운(기존에 학습되지 않은) data가 주어졌을 때, 종속변수를 제대로 예측하지 못하는 현상을 의미한다. 즉, 수학 문제집에 다시 한 번 비유해보자면, '개념원리' 문제집에 있는 문제들만 지나치게 학습한 나머지, '쎈'이나 '수능원리'와 같은 다른 문제집에 있는 수학문제들은 제대로 풀지 못하는 것과 비슷하다고 할 수 있겠다.
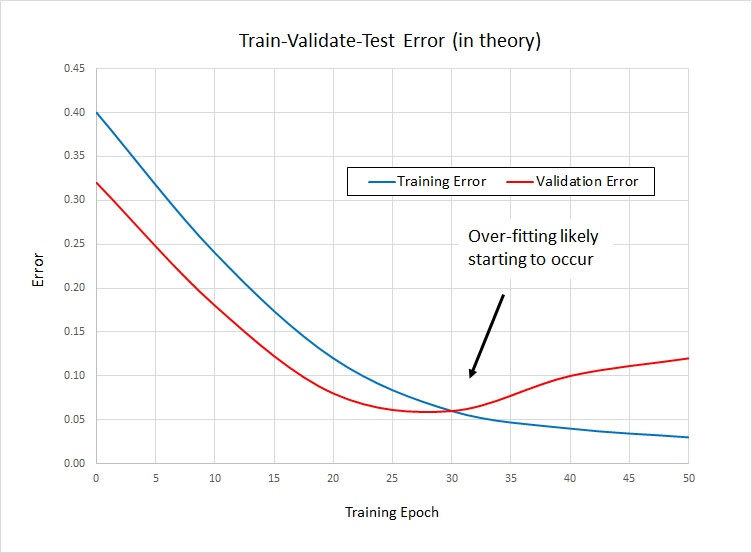
이러한 과적합 문제를 방지하기 위해 사용할 수 있는 방법 중 하나는 '검증 데이터셋(validation dataset)'을 사용하는 것이다. 원래 전체 데이터 100 중에서 80을 training set, 나머지 20을 test set으로 썼다고 한다면, 이제는 training set 80 중에서 일부를 검증 데이터셋으로 사용해, 특정 학습 횟수(training epoch)가 끝날 때마다 해당 모델의 성능을 validation set을 통해 검증하고, 에러를 구한다. 아래 그래프를 보면 파란색 그래프(training error, 학습데이터에 대한 오류)는 학습 횟수가 증가할 수록 계속 감소하는 것을 볼 수 있는데, 이는 모델이 training dataset에 점점 더 fit 되어가는 과정이다. 반면, epoch이 30을 넘는 순간 빨간색 그래프(validation error)는 상승하게 된다. 즉, 모델이 training data에 대해서는 잘 예측하지만, 새로운 데이터(validation data)에 대해서는 예측을 잘 하지 못해 해당 지점부터 validation error가 증가한다는 것을 알 수 있다. 모델이 overfit 되기 시작하는 순간이다. 따라서 training epoch이 30일 때 모델의 학습을 멈추는 것이 가장 이상적인 성능을 이끌어낸다고 할 수 있다.
3. 검증데이터(Validation Dataset)
- 특정 학습횟수가 완료될 때마다 학습된 모델에 대해 성능을 검증하기 위한 용도로 사용되는 data
- 학습 시에 validation dataset이 포함되어서는 안된다!
- training data 80%, validation data 20%가 일반적이지만, 데이터의 양과 종류에 따라 달라질 수 있다.
dataset 분리를 위해 sklearn.model_selection의 train_test_split 함수를 사용한다.
# 전체 데이터는 data, 피쳐는 data[feature], 정답은 data['label']에 할당되어 있다고 할 때
# training dataset, testing dataset 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data[feature], data['label'],
test_size=0.2, shuffle=True, random_state=42)
# training dataset, validation dataset 나누기
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train,
test_size=0.2, shuffle=True, random_state=42)